fivefilters / readability.php
A PHP port of Mozilla's Readability.js
Maintainers
Requires
- php: >=8.4
- ext-dom: *
- ext-mbstring: *
- psr/log: ^1.0 || ^2.0 || ^3.0
- rowbot/url: ^3.1.7 || ^4.0
Requires (Dev)
- phpunit/phpunit: ^12.0
- vimeo/psalm: ^6
Suggests
- ext-uri: Native WHATWG URL parsing, used automatically on PHP 8.5+ instead of rowbot/url
This package is auto-updated.
Last update: 2026-07-30 17:54:28 UTC
README
![]()
PHP port of Mozilla's Readability.js. Parses HTML (usually news stories and other articles) and returns the title, author, main content and other metadata, without nav bars, ads, footers, or anything that isn't the main body of the text.
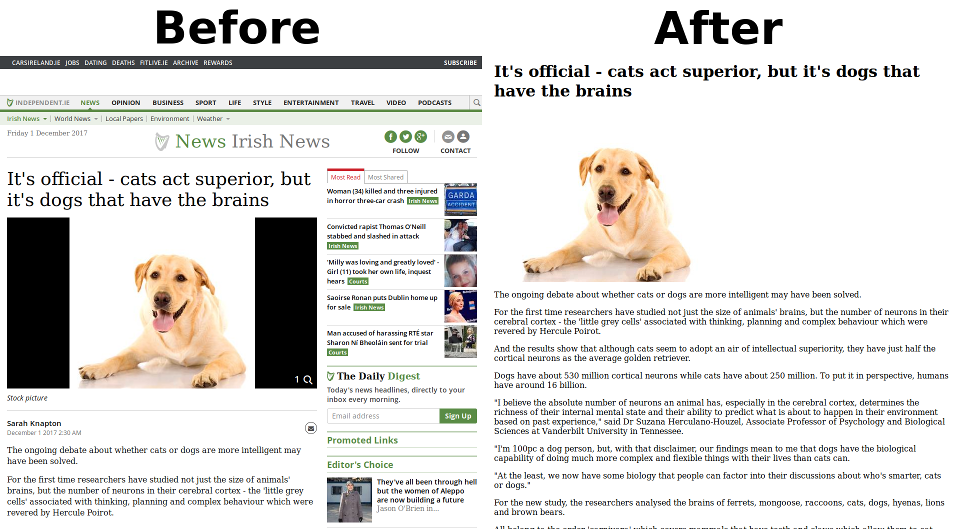
Version 4.0 is a ground-up rewrite, produced using Claude Code (Anthropic's AI coding tool), to bring the code in line with the latest version of Readability.js (v0.6.0, transcribed method-for-method) and to take advantage of the new, faster native HTML parser introduced in PHP 8.4 (Lexbor, included in the DOM extension) and the new WHATWG URL parser introduced in PHP 8.5. It parses HTML the way modern browsers do, needs no third-party HTML parsing library, and is tested against Mozilla's own test corpus.
Original Developer: Andres Rey
Developer/Maintainer: FiveFilters.org
Requirements
PHP 8.4+, ext-dom, and ext-mbstring.
How to use it
First require the library using composer:
composer require "fivefilters/readability.php:^4.0"
Then create a Readability instance and feed parse() your HTML. It returns an Article object:
<?php require __DIR__ . '/vendor/autoload.php'; use fivefilters\Readability\Readability; use fivefilters\Readability\ParseException; $readability = new Readability(); $html = file_get_contents('https://your.favorite.newspaper/article.html'); try { $article = $readability->parse($html); if ($article->hasContent()) { echo $article->content; } else { // no article content found — title and metadata are still available echo sprintf('No content found in "%s"', $article->title); } } catch (ParseException $e) { echo sprintf('Error processing text: %s', $e->getMessage()); }
When no article content can be found — the case where Readability.js returns null — parse() still returns an Article carrying whatever was extracted before content detection failed (title, byline, dir, lang, excerpt, siteName, publishedTime, image), with the content-derived properties (content, textContent, length, contentElement) set to null. Article::hasContent() tells the two apart. ParseException is reserved for the cases where parsing cannot be attempted at all: empty input, or a document exceeding maxElemsToParse (where Readability.js throws too).
Article is an immutable value object mirroring what Readability.js returns:
$article->title; // string – article title $article->content; // string – processed article HTML $article->textContent; // string – article text with all HTML removed $article->length; // int – length of textContent in characters $article->excerpt; // ?string – description or short excerpt $article->byline; // ?string – author metadata $article->siteName; // ?string – name of the site $article->dir; // ?string – content direction (ltr/rtl) $article->lang; // ?string – content language $article->publishedTime; // ?string – published time $article->image; // ?string – lead image URL (og:image/twitter:image/link) $article->images; // string[] – lead image + all content images, de-duplicated $article->contentElement; // \Dom\Element – content as a DOM element echo $article; // same as $article->content
image and images are a PHP-specific addition (Readability.js has no image extraction). When fixRelativeURLs is enabled they are returned as absolute URLs.
The content-derived properties (content, textContent, length, images) are computed from contentElement on first access and then cached, so callers that only work with the DOM element (or only check hasContent() and the metadata) never pay for serializing the article HTML and text. A consequence of the caching: if you mutate contentElement, do it before reading content/textContent — mutations made after the first read are not reflected.
So for finer control over the output, wrap the properties in your own HTML:
<h1><?= $article->title ?></h1> <h2>By <?= $article->byline ?></h2> <div class="content"><?= $article->content ?></div>
For post-processing, contentElement gives you the article as a DOM element — CSS selectors work natively:
foreach ($article->contentElement->querySelectorAll('img[src]') as $img) { $images[] = $img->getAttribute('src'); }
parse() also accepts a \Dom\HTMLDocument directly (for example because you want to pre-process it). Note that a passed document is modified in place while the article is extracted (unless the metadataOnly option is set, which guarantees a read-only pass).
Checking if a page is readerable
There is also a port of Mozilla's isProbablyReaderable: a quick-and-dirty way of figuring out if it's plausible that a page contains an article, without the cost of running the full parse. Like the original, it can produce both false positives and false negatives, but it's cheap enough to run on pages as they come in:
use fivefilters\Readability\Readerable; // Only run the full parse if we suspect it will produce a meaningful result. if (Readerable::isProbablyReaderable($html)) { $article = new Readability()->parse($html); }
It accepts an HTML string or a \Dom\HTMLDocument, and takes the same optional tuning parameters as Readability.js (same defaults):
- minContentLength: default
140, the minimum node content length used to decide if the document is readerable; - minScore: default
20, the minimum cumulated 'score' used to determine if the document is readerable; - visibilityChecker: default
Readerable::isNodeVisible(...), the function used to determine if a node is visible.
Readerable::isProbablyReaderable($html, minScore: 0, minContentLength: 120);
Options
All options have defaults, so new Readability() is all you need for the standard behavior. To change something, pass options as named arguments — the equivalent of the options object in Readability.js:
$readability = new Readability( fixRelativeURLs: true, originalURL: 'https://my.newspaper.url/article/something-interesting-to-read.html', );
If you want to build the options up separately, or share them between instances, you can also pass a Configuration — a readonly object taking the same named arguments (or an array via Configuration::fromArray()):
use fivefilters\Readability\Configuration; $configuration = new Configuration(fixRelativeURLs: true, originalURL: 'https://...'); $readability = new Readability($configuration);
Options matching Readability.js (same defaults):
- debug: default
false, log debug messages viaerror_log(). - maxElemsToParse: default
0(no limit), maximum number of elements to parse, throws when exceeded. - nbTopCandidates: default
5, the number of top candidates to consider when analysing how tight the competition is among candidates. - charThreshold: default
500, minimum number of characters an article must have for the parse to succeed. - classesToPreserve: default
[], class names to keep on elements (in addition to thepageclass Readability itself sets). - keepClasses: default
false, keep allclass="..."attributes instead of stripping them. - disableJSONLD: default
false, skip JSON-LD metadata extraction. - allowedVideoRegex: default
null(built-in list), PCRE pattern for video embed URLs allowed to stay in the article. - linkDensityModifier: default
0.0, number added to the base link density threshold during shadiness checks.
PHP-specific options (a browser knows the page URL; this library must be told):
- fixRelativeURLs: default
false, convert relative URLs to absolute. - originalURL: default
null, the URL the article was fetched from, used as the base for URL fixing. A<base href>in the document is honored too. - logger: default
null, an optional PSR-3LoggerInterface. When set, debug messages are also sent to it (independently of thedebugflag, which only controlserror_log()). - keepInlineByline: default
false. By default an inline byline (e.g. a<p class="byline">By Jane Doe</p>) is removed from the content, as in Readability.js. Set this totrueto keep it in the content; either way it is still extracted into$article->byline. - metadataOnly: default
false. Extract only the title and metadata, skipping content extraction entirely — useful when you locate the article body yourself and only want Readability's title/metadata extraction.parse()then skips every stage that mutates the document, so a passed-in\Dom\HTMLDocumentis guaranteed to be left unmodified (normally a passed document is modified in place). The returnedArticlehas the content-derived properties set tonull, as when no content is found (hasContent()returnsfalse).
Toggles for internal Readability flags carried over from earlier versions (always on in Readability.js):
- stripUnlikelyCandidates: default
true, remove nodes that are unlikely to contain relevant content. - weightClasses: default
true, weight classes during the rating phase. - cleanConditionally: default
true, remove certain nodes after parsing to return a cleaner result.
Upgrading from 3.x
The 4.0 API is new: the parse result is a readonly Article value object instead of getters on a stateful instance, Configuration uses named constructor arguments instead of setters, and a few 3.x-only features (libxml workaround options) are gone.
See UPGRADE.md for the full guide: before/after code, a mapping table for every 3.x method and option, replacement snippets for the removed features, and the behavior changes to be aware of.
Limitations
Websites that load their content through JavaScript (lazy loading, AJAX) will not have their content extracted, because JavaScript is not executed. For such content you will need to grab the HTML via a headless browser first and then give it to Readability.
Dependencies
- rowbot/url for WHATWG URL Standard relative URL resolution on PHP 8.4. On PHP 8.5+ the native
Uri\WhatWg\Urlclass is used automatically instead — the same URL parser Readability.js gets from the browser'snew URL(). - psr/log for the optional PSR-3
loggeroption (interfaces only).
Otherwise, parsing and serialization use PHP's own DOM extension.
How it works
Readability scans and scores HTML elements based on the number of words, links and type of elements contained. Then it selects the highest scoring element and tries to remove any unnecessary elements contained inside, like nav bars, empty nodes, etc.
Security
Readability is a content extractor, not a sanitizer. The returned
Article::$content (and Article::$contentElement) is HTML pulled from the
source page — it is not safe to render as-is when the input is untrusted.
If you're going to use Readability with untrusted input (whether in HTML or DOM form), we strongly recommend you use a sanitizer library like HTML Purifier or Symfony's HtmlSanitizer to avoid script injection when you use the output of Readability. We would also recommend using CSP to add further defense-in-depth restrictions to what you allow the resulting content to do. The Firefox integration of reader mode uses both of these techniques itself. Sanitizing unsafe content out of the input is explicitly not something we aim to do as part of Readability itself - there are other good sanitizer libraries out there, use them!
Readability removes <script>, <style> and <noscript> elements and
neutralizes <a href="javascript:..."> links (the latter now happens
regardless of the fixRelativeURLs setting, as a defense-in-depth measure).
This is not a substitute for a real sanitizer. In particular, the
following can survive extraction and must be handled by your sanitizer:
- Inline event-handler attributes (
onclick,onerror,onload, …). data:and other non-http(s)URIs on media —src/srcset/posterofimg/source/video/etc., including URLs promoted from lazy-loading attributes such asdata-src.- Embedded video players (
<iframe>/<embed>/<object>) that are kept when they matchallowedVideoRegex— these are preserved with all their attributes.
Two operational notes for untrusted input:
- Set
maxElemsToParse(default0, meaning no limit) and cap the raw input size yourself. The whole document is parsed into a DOM before that limit is checked, so it bounds the extraction work rather than peak parse-time memory. - Treat
allowedVideoRegexas trusted configuration. It is matched against element markup from the (possibly attacker-controlled) document, so a pathological pattern supplied here could cause catastrophic backtracking.
Development and testing
The test corpus is Mozilla's own test-pages set (plus a few PHP-specific pages), and content comparison uses a PHP port of Mozilla's structural DOM comparison, so Mozilla's expected files are used as-is.
composer install --prefer-source ./vendor/bin/phpunit
CI runs the suite (plus Psalm static analysis) on PHP 8.4 and 8.5.
Updating the expected test output
Run the suite with output-changes=1 (and optionally output-diff=1 for diffs) in the environment:
output-changes=1 output-diff=1 ./vendor/bin/phpunit
New output for any failing page (with a diff) is written to test/changed/. If you're happy with the changes, copy the new expected files over their counterparts in test/test-pages/.
Cross-checking against Readability.js
test/tools/ contains a harness that runs Mozilla's Readability.js over every test page and compares field-by-field with this port's output:
cd test/tools && npm install node cross-check.mjs php cross-check.php
Accepted differences are documented in test/tools/known-divergences.md.
License
Based on Arc90's readability.js (1.7.1) script available at: http://code.google.com/p/arc90labs-readability
Copyright (c) 2010 Arc90 Inc
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.