dynoser / base85
base85 encoder and decoder. ASCII85, vwx85, and vc85 (visually distinctive characters cyrillic)
Maintainers
Requires (Dev)
- phpunit/phpunit: 9.6.15
README
vc85 encoding is a variant of base85 (85-character chatset) and is compatible with ASCII85.
vc85: An Improved Version of ASCII85 Encoding
The enhancement lies in the addition of alternative characters to the character set, which function identically to the "primary" ASCII85 characters. The vc85 decoder is backward-compatible with ASCII85 and can decode both ASCII85 and vc85 encodings.
The vc85 character set is designed so that character codes in utf-8 and cp1251 do not overlap. Therefore, the decoder can handle all possible variants of base85, including ascii85, vwx85, and vc85. The differences between these encoding variants are as follows:
- ascii85 consists of 85 consecutive ASCII characters from
!tou, corresponding to the regular expression[!-u]. - vwx85 is similar to ascii85 but replaces three "awkward" characters:
vinstead of",winstead of',xinstead of\. - vc85, in addition to the vwx85 replacements, substitutes all special characters with Cyrillic alphabet letters that visually differ from all other characters in the table. See the table:
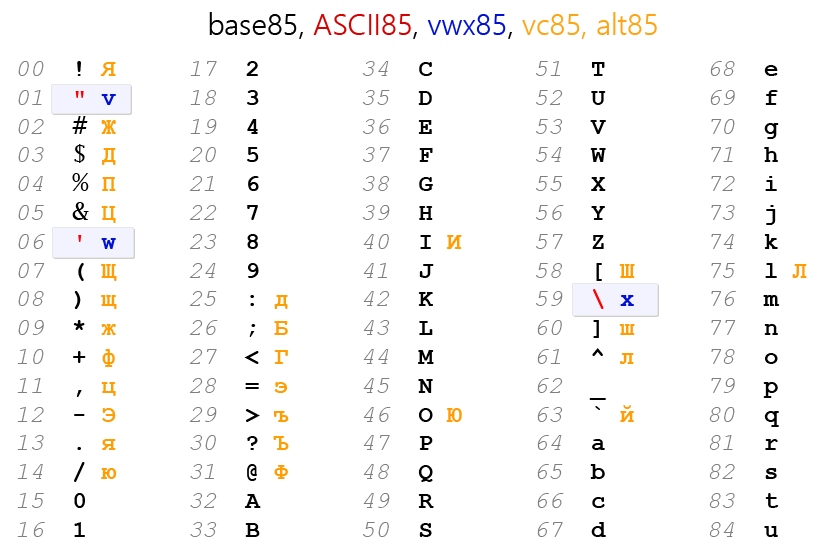
Understanding Base-85 Encoding
Base85 encoding encodes groups of 4 bytes into 5 characters, making it more compact than base64, which encodes groups of 3 bytes into 4 characters.
Implementing base85 encoding is straightforward in most programming languages. It operates on 4-byte groups that fit into 32-bit numbers, making them easy to handle compared to higher-bit numbers.
While base85 encoding could replace base64 in many scenarios, the presence of special characters complicates its use. It's not as simple as enclosing an ascii85-encoded string in quotes and inserting it into code because the string may contain quotes, backslashes, and other problematic characters.
The vwx85 variant partly addresses this issue by removing quotes and backslashes from the character set since these characters often cause problems. This substitution makes it possible to include such data almost anywhere without issues. Since the characters v, w, and x are not used in the classic ascii85 variant, this substitution seems a logical solution to many problems.
Characters z and y
As historically, the characters z and y were used to encode 5 null bytes and 5 spaces, respectively, the vc85 decoder also supports these rules.
Prefixes and Suffixes
Since the base85 character set does not include the tilde ~, it can be used as a marker to indicate the end of encoded data. In the complete format, data in base85 encoding is enclosed between <~ at the beginning and ~> at the end of the encoded data block.
The current vc85 decoder implementation trims decoded data based on these prefixes and suffixes. If <~ is found in the data, all preceding data will be discarded. Similarly, if ~> is encountered, all subsequent data will be discarded.
Whitespace Characters
Spaces and line breaks are ignored and can appear anywhere.
Representations in utf-8 and cp1251
The Cyrillic characters added to the vc85 charset can be represented in utf-8 or cp1251 encodings. The decoder understands both variants. It's worth noting that in cp1251, all characters are represented by 1-byte codes, while in utf-8, Cyrillic characters are represented by two-byte codes (starting either with 208 or 209). In this implementation, when decoding utf-8, codes 208 and 209 are removed, resulting in one-byte encoding. Therefore, no conversions between utf-8 and cp1251 are required.
Usage (for PHP)
To use vc85, simply include the file vc85.php.
For encoding data, use the static function encode, and for decoding, use the static function decode.
Example code:
<?php use dynoser\base85\vc85; // Include to use the short name vc85 require_once 'src/vc85.php'; // Manually include the file if autoloading is not used. Provide the correct path. vc85::init(3); // (Optional) Initialize the encoder with vc85 mode. By default, mode 2 (vwx85) is used. $en = vc85::encode("Some data"); // Encode some data in vc85 echo $en; // Display the result $de = vc85::decode($en); // Decode back into a byte string
The result will be something like:
<~БfЪMaфCnoЦФю~>
Control Over Prefixes
To disable or enable the addition of <~ ... ~> at the beginning and end:
vc85::$addPf = false; // false - do not add, true - add. By default, it adds.
Control Over Line Breaks
To output the encoder result in one line (without breaks) set 0, or for line breaks at a specified width, set a number to the static variable $splitWidth:
vc85::$splitWidth = 0; // 0 - do not break into lines. Default is 75, breaking into lines of 75 characters.
Choosing Encoding Mode
To initialize the encoder for the desired charset, call init with a parameter. Options:
vc85::init(1); // Encoder will output data in classic ASCII85 format. vc85::init(2); // (Default) - output in vwx85 format (replaces `"` with `v`, `'` with `w`, `\` with `x`). vc85::init(3); // vc85 (special characters replaced with Cyrillic characters in utf-8 encoding). vc85::init(4); // Same as 3, but Cyrillic characters represented in cp1251 encoding.